
.svg)
Detecting NGINX Worker Leaks

A good way to understand how software systems work is through studying how they fail. It's why the Prequel Reliability Research Team (PRRT) are big fans of Google's Project Zero blog [1].
We love sharing stories and learning with a community of people. It's in that spirit our team decided to publish our research into software and reliability problems. Follow us along on the journey!
Introduction
Ingress-NGINX is a widely-used reverse proxy and load balancer in Kubernetes environments [2]. It is built with the Ingress resource to make it easier to expose services to users.
We recently observed some hard-to-detect problems in production with ingress-nginx controllers. This blog explains each problem, how to detect it, and how to mitigate it using tools like https://github.com/prequel-dev/preq (try it out and give it a 🌟).
Problem: CPU Cores Cause Silent Worker Crashes
Unfortunately there weren't many observed symptoms for this problem.
End users reported intermittent degradation of API endpoints. During the reported times, the [alert] pthread_create() failed log message appeared in ingress-nginx controller logs.
2025/05/20 14:39:05 [alert] 1496#1496: pthread_create() failed (11: Resource temporarily unavailable)
We also observed a configuration reload event at the same time:
ingress-nginx 43m Normal RELOAD
No crashes or HTTP request errors were observed.
During the investigation, the following related issues were found:
- cri-o #5779 [3]
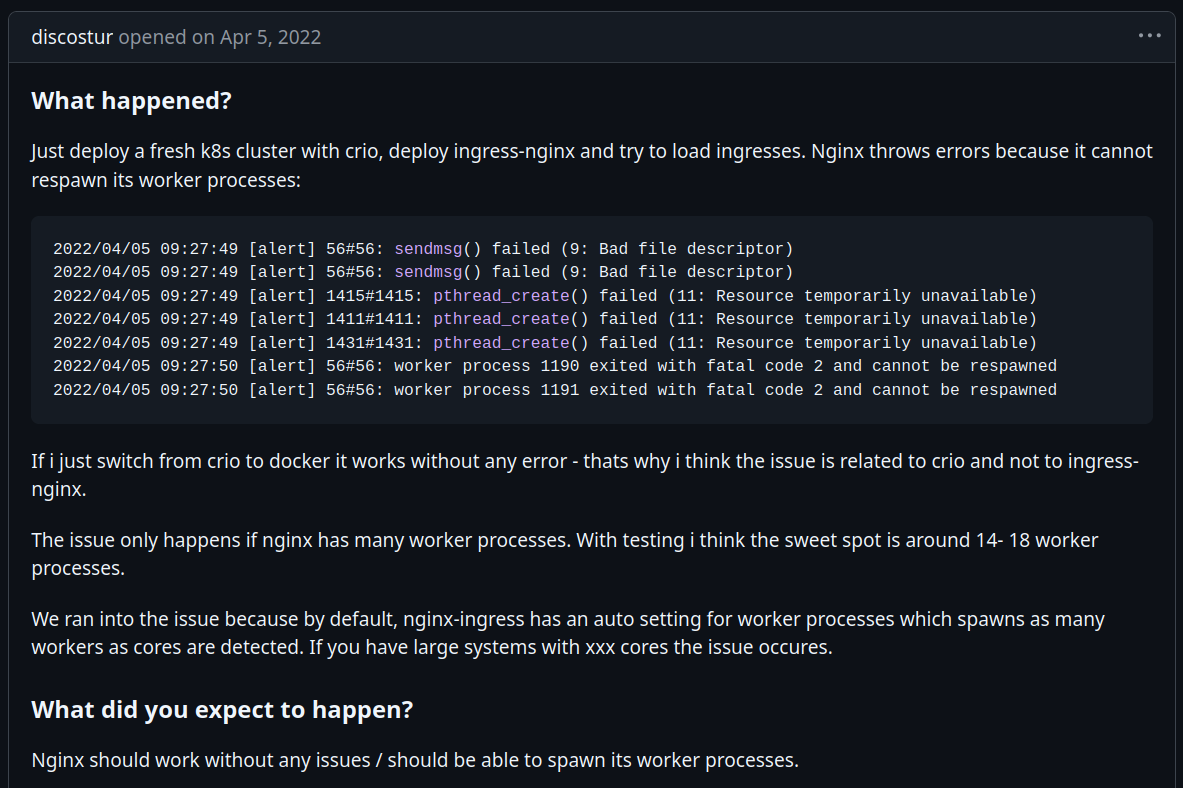
- data-prep-kit PR #81 [4]

- ingress-nginx #6141 [5]

- ingress-nginx #4576 [6]

Because the symptoms described in related issues are similar to our observed problem, we started our reproduction with the hypothesis that the problem was related to configuring and scaling NGINX workers.
For background, NGINX starts multiple worker processes within the ingress-nginx-controller container. Each worker handles incoming requests on ingress resources and route them to the appropriate service endpoint [7].
PID VSZ %VSZ CPU %CPU COMMAND
7 725m 9% 1 0% /nginx-ingress-controller --publish-service=ingress-nginx/ingress-nginx-controller --election-id=ingress-controller-leader --controller-class=k8s.io/ingress-nginx --ingress-class=nginx --config
33 153m 2% 1 0% nginx: worker process
36 153m 2% 1 0% nginx: worker process
34 153m 2% 0 0% nginx: worker process
35 153m 2% 0 0% nginx: worker process
28 142m 2% 1 0% nginx: master process /usr/bin/nginx -c /etc/nginx/nginx.conf
37 140m 2% 0 0% nginx: cache manager process
The default number of worker processes for the ingress-nginx controller is equal to the number of CPU cores [8].
bash-5.1$ cat /proc/cpuinfo | grep processor | wc -l
4
During the reproduction phase of the investigation, it was noted the ingress-nginx controller deployment used the following memory limits:
resources:
requests:
cpu: 100m
memory: 90Mi
limits:
memory: 200Mi
And the underlying node in the Kubernetes cluster was m5.16xlarge with 96 vCPU:
Capacity:
cpu: 96
memory: 384Gi
pods: 110
Allocatable:
cpu: 96
memory: 383Gi
pods: 110
After setting up an exemplar environment with the same number of CPUs, we deployed the same configuration and observed silent out-of-memory (OOM) crashes for worker nodes within the container [9, 10]:
May 22 02:43:17 kernel: oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=aba6a64a8753ea5169d3f501d661492696ffeb640da38c613b81198435144dcd,mems_allowed=0-1,oom_memcg=/kubepods/burstable/poddfc7f441-06db-11ea-842a-0227fba247b6,task_memcg=/kubepods/burstable/poddfc7f441-06db-11ea-842a-0227fba247b6/aba6a64a8753ea5169d3f501d661492696ffeb640da38c613b81198435144dcd,task=nginx,pid=22232,uid=0
May 22 02:43:17 kernel: Memory cgroup out of memory: Kill process 22232 (nginx) score 1182 or sacrifice child
And we observed the same errors in the ingress-nginx controller logs:
2025/05/21 16:08:07 [alert] 27#27: sendmsg() failed (9: Bad file descriptor)
2025/05/21 16:08:07 [alert] 27#27: fork() failed while spawning "cache loader process" (11: Resource temporarily unavailable)
2025/05/21 16:08:07 [alert] 27#27: sendmsg() failed (9: Bad file descriptor)
2025/05/21 16:08:07 [alert] 27#27: sendmsg() failed (9: Bad file descriptor)
As others had done in the issues above, we added a `worker-processes` limit to our deployment configuration. This fixed the problem in production.
PRRT created a new CRE rule PREQUEL-2025-0071 to detect this problem. CREs—Common Reliability Enumerations—are standardized rules that describe specific reliability problems, including their symptoms, root causes, and common mitigations.
CREs are used to scan observability data in real time to proactively surface failure patterns.
You can find detections for each problem in this blog at the end of this blog post.
Problem: Lua Snippet Leaks
Another worker memory leak was observed by PRRT in a different ingress-nginx controller configuration.
The following log message was observed during the problem:
2025/05/06 21:00:20 [alert] 961#961: fork() failed while spawning "worker process" (12: Cannot allocate memory)
An Ingress object on the controller is using an `nginx.ingress.kubernetes.io/configuration-snippet` annotation to use a Lua script to implement an adaptive cache on requests to a specific endpoint [11].
If a request has a cache miss, it returns stale data but starts a timer to refresh the cache asynchronously. While this guarantees only one refresh per key at scale, the side effect is any memory used by the timer accumulates in the worker process per request.
-- spawn refresh if no one else is doing it
if inflight:add(key, true, STALE_TTL) then
local ok, err = ngx.timer.at(0, refresh_cb, key, fetch)
if not ok then
ngx.log(ngx.ERR, "[adaptive_cache] timer error: ", err)
inflight:delete(key)
end
end
After enough requests with cache misses, the worker processes consumed too much memory and hit silent OOM crashes in the controller container.

As others in the community have noted, request processing with Lua should avoid using timers [12]. After this anti-pattern was fixed, the problem was mitigated.
Common Reliability Enumerations
The following CRE rules were created to detect these problems.
PREQUEL-2025-0071
This CRE rule uses a correlation window across NGINX controller logs, Kubernetes events, and process OOMs (including silent worker OOM crashes) to detect the CPU Cores Cause Silent Worker Crashes problem above.
rules:
- cre:
id: PREQUEL-2025-0071
severity: 0
title: CPU Cores Cause Silent ingress-nginx Worker Crashes
category: proxy-problems
author: Prequel
description: |
The ingress-nginx controller worker processes are crashing because there are too many for the limits specified for this deployment.
cause: |
The default number of NGINX worker processes is derived from the number of CPUs available on the node. When deployed on nodes with large vCPU, combined with memory limits, the end result is silent worker process OOMs as worker processes handle configuration reloads and updates.
impact: |
User-facing API endpoints experience degrated connectivity. Unreliable connections and timeouts are common.
tags:
- nginx
- known-problem
mitigation: |
- Set a specific limit of worker processes using the `worker-processes` configuration option
- Increase the memory limits for the controller on larger nodes
references:
- https://github.com/kubernetes/ingress-nginx/issues/6141
- https://github.com/kubernetes/ingress-nginx/issues/4756
- https://github.com/cri-o/cri-o/issues/5779
- https://github.com/data-prep-kit/data-prep-kit/pull/81
applications:
- name: "nginx"
metadata:
kind: prequel
gen: 1
rule:
set:
window: 1s
match:
- set:
event:
source: cre.log.nginx
origin: true
match:
# Match on the worker alert error messages
- regex: "alert(.+)Resource temporarily unavailable|failed while spawning(.+)Cannot allocate memory"
- set:
event:
source: cre.prequel.process.oom
match:
# If the Prequel OOM data source contains a new entry with a group ID, then trigger the rule.
- regex: "\"comm\"\\s*:\\s*\"nginx\""
- set:
event:
source: cre.kubernetes
match:
- regex: ingress-nginx(.+)RELOAD(.+)NGINX reload triggered due to a change in configuration
PREQUEL-2025-0076
This CRE rule uses a correlation window across NGINX controller logs, Ingress configuration containing Lua code, and process OOMs (including silent worker OOM crashes) to detect the Lua Snippet Leaks problem above.
rules:
- cre:
id: PREQUEL-2025-0076
severity: 0
title: Lua timers anti-pattern used in NGINX request processing
category: proxy-problems
author: Prequel
description: |
The application spawns a new `ngx.timer.at()` (or `ngx.timer.every()`) inside the hot-path of every HTTP request. Each timer retains its callback closure and any captured data for the lifetime of the NGINX worker.
When traffic is sustained—or when the timer re-arms itself—this pattern causes unbounded growth of:
* Lua heap (each closure / payload that the GC can’t reclaim)
* NGINX timer queue (extra per-timer bookkeeping in C memory)
* Context switches (each timer callback runs in its own coroutine)
Eventually the worker reaches its memory limit, is OOM-killed, or starves CPU time, leading to 5xx responses and connection resets.
cause: |
* Developer places `ngx.timer.at()` inside `access_by_lua*`, `content_by_lua*`, or `rewrite_by_lua*`, so **every** client request schedules a timer.
* Callback captures large tables / strings or recursively reschedules itself (`ngx.timer.at(delay, cb)`) without a stop condition.
* No guard (e.g., shared-dict flag) to ensure only one in-flight timer per logical task, resulting in thousands of duplicate timers.
impact: |
User-facing API endpoints experience degrated connectivity. Unreliable connections and timeouts are common.
tags:
- nginx
- known-problem
mitigation: |
* **Move background work** to `init_worker_by_lua_block` and create one global `ngx.timer.every()` per task.
* **Coalesce per-request work**: use a shared-dict “in-flight” key so only the first request starts a timer; others reuse the result.
* **Keep payloads small**: pass IDs to the timer, fetch heavy data inside the callback; avoid capturing > KB-sized tables/strings.
* **Honor `premature`** in callbacks and cancel long-running retries.
* Add memory alerts (`collectgarbage("count")`, RSS) and a hard worker
memory limit so leaks fail fast in staging.
references:
- https://github.com/openresty/lua-nginx-module#ngxtimerat
applications:
- name: "nginx"
metadata:
kind: prequel
gen: 1
rule:
set:
window: 1s
match:
- set:
event:
source: cre.log.nginx
origin: true
match:
# Match on the worker alert error messages
- regex: "alert(.+)Resource temporarily unavailable|failed while spawning(.+)Cannot allocate memory"
- set:
event:
source: cre.prequel.process.oom
match:
# If the Prequel OOM data source contains a new entry with a group ID, then trigger the rule.
- regex: "\"comm\"\\s*:\\s*\"nginx\""
- set:
event:
source: cre.config.nginx.ingress
match:
- regex: ngx.timer.at
Download preq at https://github.com/prequel-dev/preq to try out rules like these and other open source CREs (and give it a 🌟).
Follow us for more content like this:
References
1. https://googleprojectzero.blogspot.com/
2. https://github.com/kubernetes/ingress-nginx
3. https://github.com/cri-o/cri-o/issues/5779
4. https://github.com/data-prep-kit/data-prep-kit/pull/81
5. https://github.com/kubernetes/ingress-nginx/issues/6141
6. https://github.com/kubernetes/ingress-nginx/issues/4756
7. https://github.com/kubernetes/ingress-nginx/blob/f0f2db512fc88e6e558d9672e9947a5ddd6e530e/docs/user-guide/nginx-configuration/configmap.md#worker-processes
8. https://github.com/kubernetes/ingress-nginx/blob/f0f2db512fc88e6e558d9672e9947a5ddd6e530e/docs/user-guide/nginx-configuration/configmap.md#configuration-options
9. https://medium.com/@reefland/tracking-down-invisible-oom-kills-in-kubernetes-192a3de33a60
10. https://github.com/kubernetes/kubernetes/issues/117070#issuecomment-1494679542
11. https://docs.nginx.com/nginx-ingress-controller/configuration/ingress-resources/advanced-configuration-with-snippets/
12. https://github.com/openresty/lua-resty-upstream-healthcheck/issues/69




