
.svg)
Community: The 100% Open-Source AI Stack That Automates My Business, and Tricks for Troubleshooting It
.png)
Most teams don’t need a full fledged “AI platform” to automate everyday workflows. You need a reliable way to trigger automation jobs, call a model, keep a little context, and deliver results. That’s it.
In this guide I’ll show my practical, open-source AI stack for automating my business workflows. For me, it was important for my stack to be 100% open source and self-hosted. There are certainly shortcuts you can take with commercial LLMs or other components.
In short, I landed on n8n for orchestration, Ollama for LLM server, and Postgres + pgvector for memory/RAG.
I also developed a simple deployment playbook with k8s extensibility and tips for keeping it reliable and healthy as you go.
Why an Open-Source stack
If you’re handling customer data, internal docs, or anything with compliance implications, running locally or on your own cloud removes a ton of uncertainty. With this stack, your prompts, retrieved snippets, and outputs live inside your network, not on somebody else’s infrastructure. You can log exactly what you want, keep tokens from leaking, and reason about costs in traditional terms (CPU/RAM/disk) instead of foggy per-token math.
There’s also the control aspect. Open tools are swappable. Don’t like the model? Pull a different one. Need to move from a laptop to on-prem? Bring your Kubernetes manifests and go. And because these projects are community-driven, you can read the code, file issues, or extend them when you bump into edge cases, no waiting for a vendor.
Oh, yeah, and for me cost mattered here.
A simple open-source AI stack that just works
At a high level, the flow is straightforward: a trigger fires in n8n (a webhook, a cron, or an event); you fetch context from APIs or files; you optionally search prior knowledge in Postgres + pgvector; you call the model via Ollama; then you save results and push them to Slack, email, the CRM, or a dashboard. That single loop covers a surprising amount of basic business flows like
- Sending a daily team update
- Sorting and replying to customer support requests
- Enriching lead details before they go into the CRM
- Turning meeting transcripts into notes, or
- Answering questions about company policies
Why these three?
- n8n gives you a visual, testable pipeline with retries, branching, and a good set of built-in nodes. You can keep 90% of the logic declarative and drop into a “Code” node only where it helps.
- Ollama is one of the most popular low-friction platforms to serve local models: one command to pull, a tiny HTTP API to call. No GPU required for small/quantized models; if you do have one, it’ll happily use it.
- Postgres + pgvector turns your database into a memory store. You can keep workflow state, results, and embeddings in one place, with real indexing and backups, no extra vector service to run.
Do you really need LangChain / AutoGPT / vLLM?
These are great AI tools, but you probably don’t need them to add value to your workflow on day one.
- LangChain is great if you're building complex chains, tool routing, or evaluators as a codebase of their own. If your flows are mostly linear (“get data - retrieve context - prompt - send”), n8n’s nodes plus a small Code step are usually simpler to reason about and maintain.
- AutoGPT (or other agent frameworks) is useful when the task is genuinely open-ended and needs autonomous planning (“research X, compare Y, produce Z unless blocked”). For business automations, most tasks are bounded: summarize, classify, extract, transform. Agentic loops can add latency and instability you don’t need yet.
- vLLM is a fantastic serving stack when throughput, long context, or GPU batching are your constraints. If you’re running a handful of concurrent automations, Ollama is much easier operationally.
Rule of thumb: begin with n8n + Ollama + pgvector. If a real bottleneck appears, too many concurrent requests, prompts that need long contexts, or tasks that require autonomous planning then layer on the specialized tool that solves that bottleneck and nothing else.
My Workflow Architecture
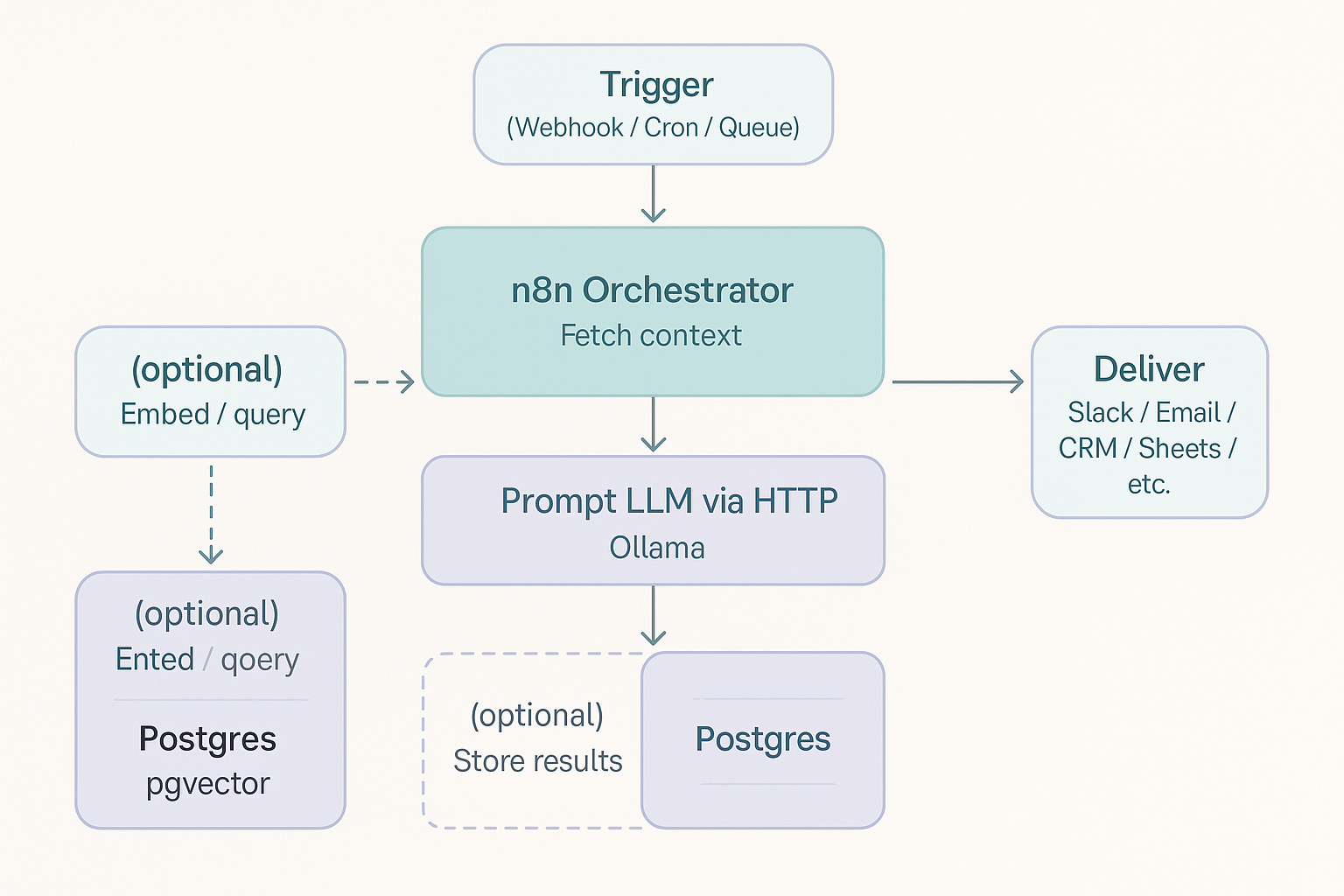
In practice you’ll add a few niceties:
- Keep prompts tidy: write down a handful of prompt templates you actually use (for summaries, classifications, replies, etc.) and save them in Postgres.
- Avoid duplicates: if you run daily jobs, store a hash of the input. If you’ve already seen it, skip re-processing. This saves time and avoids sending the same Slack message or email twice.
- Log what happens: after each step, record start time, end time, and status in the database. When something feels slow or fails silently, you’ll have a clear history instead of guessing.
Run it locally (Docker Quick Start)
You can run the stack locally in 10 minutes with Docker. We’ll run everything in containers. Postgres + pgvector, n8n, and Ollama, so n8n can call the model at http://ollama:11434 on the internal Docker network.
Prerequisites
- Docker Desktop (or Docker Engine) with Compose v2
- Optional: psql client for quick DB checks
1) Project layout
mkdir -p ai-stack/{pg-data,n8n-data,init}
cd ai-stack
Create two files:
docker-compose.yml
services:
postgres:
image: pgvector/pgvector:pg16
environment:
POSTGRES_USER: aiuser
POSTGRES_PASSWORD: supersecret
POSTGRES_DB: ai
ports:
- "5432:5432" # change left side if 5432 is busy on host
volumes:
- ./pg-data:/var/lib/postgresql/data
- ./init:/docker-entrypoint-initdb.d
healthcheck:
test: ["CMD-SHELL","pg_isready -U aiuser -d ai"]
interval: 5s
timeout: 5s
retries: 20
restart: unless-stopped
n8n:
image: n8nio/n8n:latest
ports:
- "5678:5678" # change left side if 5678 is busy on host
environment:
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n
- DB_POSTGRESDB_USER=aiuser
- DB_POSTGRESDB_PASSWORD=supersecret
- N8N_BASIC_AUTH_ACTIVE=true
- N8N_BASIC_AUTH_USER=admin@example.com
- N8N_BASIC_AUTH_PASSWORD=changeme
- N8N_DIAGNOSTICS_ENABLED=false
- N8N_RUNNERS_ENABLED=true
depends_on:
postgres:
condition: service_healthy
volumes:
- ./n8n-data:/home/node/.n8n
restart: unless-stopped
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434" # change left side if 11434 is busy on host
volumes:
- ./models:/root/.ollama # cache models on your disk
healthcheck:
test: ["CMD","/bin/sh","-c","curl -sf http://localhost:11434/api/tags || exit 1"]
interval: 10s
timeout: 5s
retries: 30
restart: unless-stoppedinit/00-init.sql
-- DB for n8n to store workflows/executions
CREATE DATABASE n8n WITH OWNER aiuser;
-- Enable vector in 'ai' DB and a tiny log table
\connect ai
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE IF NOT EXISTS llm_runs (
id BIGSERIAL PRIMARY KEY,
prompt TEXT NOT NULL,
model TEXT NOT NULL,
response TEXT NOT NULL,
latency_ms INTEGER,
created_at TIMESTAMPTZ DEFAULT now()
);
Bring the stack up:
docker compose up -d
2) Pull a small model (inside the Ollama container)
docker exec -it ollama ollama pull llama3.2
Sanity checks:
- list models (in container)
docker exec -it ollama curl -s http://localhost:11434/api/tags | jq .- check pgvector is enabled
psql -h localhost -U aiuser -d ai -c "SELECT extname FROM pg_extension;"
Open n8n at http://localhost:5678. On first visit, you’ll see a basic-auth prompt (admin@example.com / changeme), then n8n will ask you to create the Owner account (email/password).
Reliability Issues - what it breaks and how to stay ahead of it quickly
Self-hosting open source projects definitely comes with its own challenges. You are on the hook to keep it up and running. There is no support team to call.
Here are some of the gotchas I ran into and how I handle them.
Detect issues early with community CREs (and preq)
The reliability community has started to maintain a community-driven catalog of failure patterns called CREs(Common Reliability Enumerations) so you don’t have to rediscover them in production. Each CRE includes detection as code.
You can run these with preq (pronounced preek), the open source reliability problem detector, to turn noisy logs into clear, actionable signals.
The public catalog covers dozens of popular technologies, from Kubernetes and databases to application runtimes. Here are a few relevant ones my AI stack or similar ones:
You can wire detections to Slack, email, or even Jira with a short runbook (“what it means” and “what to do”) to make fixes faster.
If you are setting up this stack, or your own, set aside 10 minutes to download preq and run it. It’s open source, and it will save you from the dreaded “why did this silently fail?” mornings. Begin with the n8n data-loss rule, a basic Kubernetes exit code/DNS rule if you are running clusters, and a Postgres disk or connections check. You can always add more as your workflows grow.
👉 Explore the full CRE catalog; try out preq, and if you find it useful, don’t forget to ⭐ the repo to support the community. : )
References
- n8n docs: https://n8n.io/docs
- Ollama – repo: https://github.com/ollama/ollama
- Postgres + pgvector – https://github.com/pgvector/pgvector
- Kubernetes – https://kubernetes.io/docs/home/
- CREs (Common Reliability Enumerations) – https://github.com/prequel-dev/cre
- Preq (run CREs) – https://github.com/prequel-dev/preq




